Last year I was at a customer site implementing Hyper-V. It was all new; 3 node Hyper-V 2012 R2 cluster running on HP DL380s, 10Gig iSCSI network and a new HP 3PAR for storage. Pretty standard kit, all fully patched, latest windows patches and a few hotfixes, latest HP support pack installed, 3PAR at the latest MU, generally it seemed to be working well. That was until we did some further testing, copying data into a VM in the environment seemed to be slow.
- Copying data from outside to a Host’s c:\ – no problem
- Copying data from outside to a Host’s c:\ClusterStorage\Volume<> – no problem
- Copying data from outside in to a powered off VM’s .vhdx file – no problem
- Copying data between hosts – no problem
- Copying data out of the environment to a PC on the LAN from a VM, Host, anywhere in fact – No problem
- Copying data to a running VM, from inside the environment or outside – performance issue.
This all looks like this:
Copy a random file, we used random 5GB backup flat files. As you can imagine I did lots of testing, changing owner of VM, CSV, dynamic .vhdx files, fixed .vhdx files just to get to the bottom of the issue.
Here we are copying into a fixed .vhdx and then a dynamic .vhdx.


As it can be seen, there are no issues here, and the file copy take about 23 seconds. Repeat this and copy a file externally into a running VM and we get a very different picture:


Through put drops off massively and the total copy takes nearly 10 minutes. While repenting theses tests I noticed that we did not always get this burst of fast through put if I performed another copy straight away. This made me look further into the performance stats and noticed something more peculiar. Even though the windows GUI was saying the copy had finished the disk queue length on the VM was still high for some time after the copy had “finished”. This was also noticed in the performance of the VM while the copy was in progress and for some time after it had finished. Performance of the VM did not retune until the disk queue depth has dropped.
To investigate this further I performed more copies with different size files, noting when we see the drop off, when the GUI says the copy had finished and when disk queue length suggested the copy to disk had actually finished. The table below shows these findings:
|
From |
To |
File size |
%drop off |
GUI time of copy (waiting for disk IO to drop and Queue Length to drop) |
|
External source |
VM c:$ |
5GB |
32% |
9:47 (10:29) |
|
External source |
VM c:$ |
2.5GB |
63% |
2:55 (5:10) |
|
External source |
VM c:$ |
1.5GB |
None |
0:14 (3:28) |
|
External source |
VM c:$ |
3GB |
53 |
4:38 (6:34) |
If you then take the % drop as a size of the file it’s seen that the drop off happens after approximately 1.6GB of the file has been copied. Also the time taken for the queue length to return is also linier based on the file size.
This then made me think about buffers, VMQ for example, what’s configured with a 1.6GB buffer??? After many changes with VMQ and other setting I found nothing, so I turned my focus to the storage and this lead me to find something interesting and to ultimately finding a solution.
The 3PAR in question is a 7200 so has four iSCSI target IPs, the servers have two iSCSI dedicated NICs non teamed, and there is a single iSCSI network, giving a possible total of 8 paths per host.
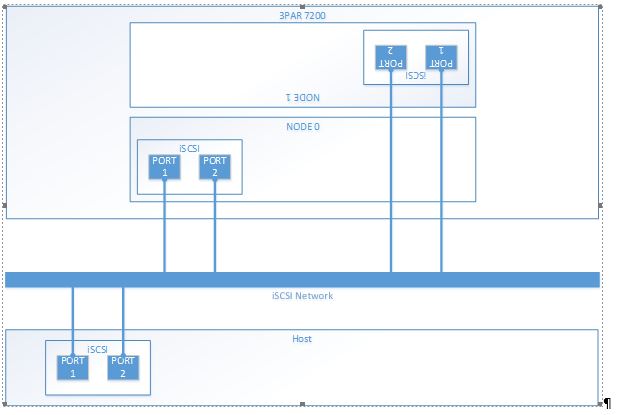
By reconfiguring iSCSI on the hosts so that each one only has two paths the problem went away completely. I tried many confutations and found anymore than two paths and the problem re-appeared. Sluggish VMs during a copy also went away with only two paths and when the GUI said the copy had finished, the disk activity also dropped as you’d expect.
When I had four or even eight paths configured and I was in the middle of a large copy and through put had dropped off, I also found that if I dropped an iSCSI NIC on a host after a small period of time the copy throughput would increase back to the original speed.
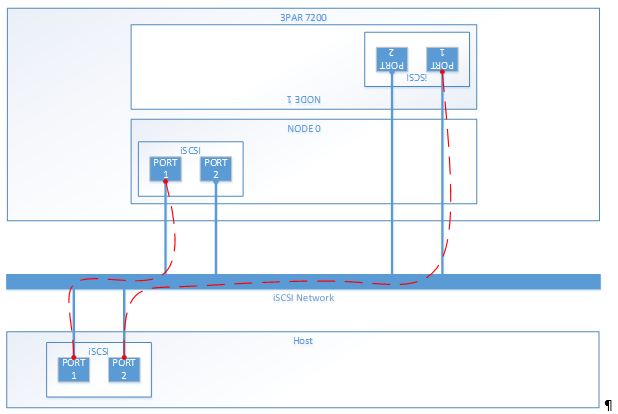
To share the load on the 3PAR ports I configured alternate servers to use odd or even ports:
Host 1:
Host 2:
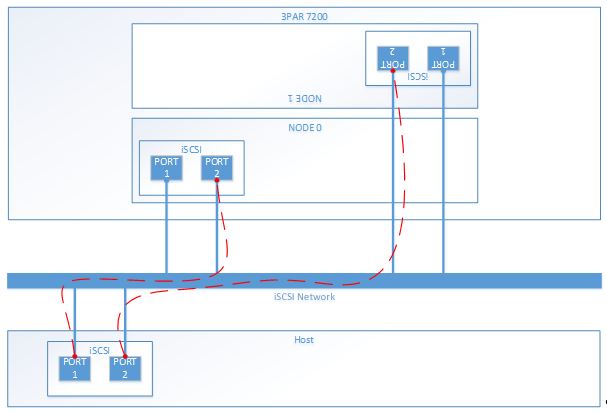
And so on. This configuration is still completely resilient and is performing well. I believe there is an issue with MPIO and how it may swap paths during the copy. I have a open call with Microsoft and if there is an update I’ll post it here.
Hope this helps someone out there who is pulling their hair out like I was.
Update – 23 May 2016
It took some time for Microsoft to come back to me, I think it was more until it got escalated to the right person but the following is their advice. I’ve not had the chance to test this yet but it makes sense what they are suggesting.
So to summarise, I found that I had to have only two paths configured out of a possible eight to stop the issue of slow performance. Microsoft’s advice is this:
- Configure all eight paths, however don’t use round robin which is the default.
- Set only two paths as active and the other six as standby.
Don’t forget to use two resilient paths. By using this configuration swapping of paths is not likely to occur during a large transfer of data, but other paths are available is there is a significant failure in the environment. It’s also unlikely that a single 10Gig NIC would become totally saturated as being used here.
If I manage to get this tested I will report back.

Thank you for posting this article. I am experiencing the exact issue and this points me in the right direction.
LikeLike
Thank you! We have same issue and reply from L2 HP is that 10Gb iSCSI ports on controllers have too small cache witch is getting overflow. They said newer adapters should be fine…
LikeLike
No problem, glad it’s out there and still helping people. Interesting what HPE have said.
LikeLike